
Unit 2 - Database Design
What I Learned – Breaking Down the Key Concepts
Understanding the Database Design Process
Before building a database, you have to plan it properly. Just throwing data into tables without structure leads to chaos. The design process involves:
- Figuring out what data is needed and how it will be used.
- Identifying key entities, attributes, and relationships (like students enrolling in courses).
- Structuring everything into a logical schema before actually creating the database.
Relational Modeling – Making Sense of Data
The relational model is all about organizing data into tables (relations) where:
- Rows (tuples) store individual records.
- Columns (attributes) hold specific details.
- Keys (Primary, Foreign) help link different tables together.
This model keeps things structured and consistent while making it easier to retrieve and update data.
ER Diagrams – The Blueprint of a Database
Entity-Relationship (ER) diagrams help visualize the relationships between different parts of a database before implementing them. They include:
- Entities (things like students, courses, products).
- Attributes (properties like student names, course IDs).
- Relationships (connections, e.g., “students enroll in courses”).
It’s basically a map of how everything connects, making the actual database easier to build.
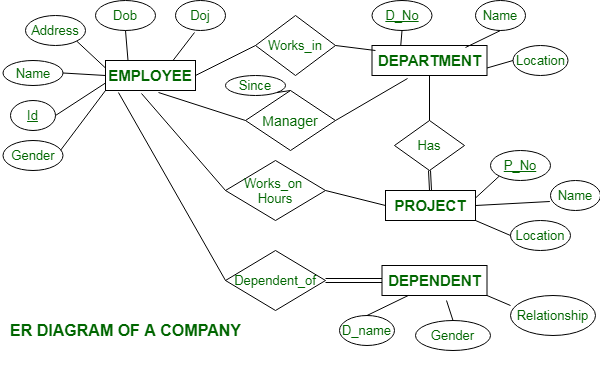
Attributes: More Than Just Data Fields
Attributes can be simple (like age) or composite (like full name, which splits into first and last name). Some are single-valued (one date of birth per person), while others are multi-valued (a person can have multiple phone numbers). Derived attributes (like calculating age from birthdate) help keep data efficient.
Mapping Cardinalities – Defining Relationships
Not all relationships are the same! Some are:
- One-to-One (1:1) – One country, one president.
- One-to-Many (1:M) – One teacher, multiple students.
- Many-to-Many (M:N) – Students enroll in multiple courses, and each course has multiple students.
The Role of Primary Keys
Every table needs a Primary Key—a unique identifier for each record (like Student ID). This keeps data organized and prevents duplicates.
Avoiding Redundancy – Why Less is More
Without proper structure, data can get repetitive, making updates a nightmare. Normalization helps by:
- Organizing tables logically.
- Preventing anomalies when adding, updating, or deleting records.
- Keeping data efficient and clean.
Turning ER Diagrams into Real Databases
To actually implement a database, you have to:
- Convert entities into tables.
- Use foreign keys to define relationships.
- Handle weak entities that depend on others for identification.
Advanced ER Features – When Things Get Complex
Sometimes, a simple ER diagram isn’t enough. Extended ER features help with:
- Generalization: Combining similar entities (e.g., “Car” and “Truck” into “Vehicle”).
- Specialization: Splitting entities into subcategories (e.g., “Employee” into “Manager” and “Technician”).
- Aggregation: Representing relationships between relationships (like linking a “Supplier-Contract” relationship to a “Company”).
Challenges in Database Design
Some of the common pitfalls in designing databases include:
- Poorly defined relationships that cause confusion.
- Weak entities that need extra support.
- Redundant attributes making everything messy.
Other Ways to Model Data
Besides ER diagrams, there are other ways to model data, like:
- Unified Modeling Language (UML) – Popular in object-oriented design.
- Object-Role Modeling (ORM) – Focuses more on describing facts than entities.
Why ACID Matters in Databases
Ever wondered how databases stay reliable even when things go wrong? That’s where ACID properties come in:
- Atomicity: Everything in a transaction happens, or nothing happens (no half-finished bank transfers).
- Consistency: The database remains valid no matter what.
- Isolation: Transactions don’t interfere with each other.
- Durability: Data doesn’t disappear even after a system crash.
Relational Algebra – The Logic Behind Queries
Designing a database is one thing, but making sense of the data inside it? That’s where Relational Algebra comes in. It’s like the blueprint for SQL queries, defining how data should be retrieved, combined, and filtered in a structured way.
At first, it seemed like just a bunch of mathematical symbols, but now I see it’s the key to writing efficient queries. Some of the main operations include:
- Selection (σ) – Think of this as a filter; it picks out specific rows based on conditions (e.g., finding students enrolled in a certain course).
- Projection (π) – Instead of showing everything, it selects only the columns you need (e.g., just names and grades).
- Union (∪) & Intersection (∩) – These combine tables, either merging all records or just the ones they have in common.
- Difference (-) – Shows what’s in one table but not the other, like finding customers who haven’t made a purchase.
- Cartesian Product (×) & Joins (⨝) – These connect data across tables, with joins being the smarter way to do it (otherwise, you’d get a huge mess of combinations!).
Why It Matters:
- Efficiency: It makes data retrieval faster, ensuring that systems run smoothly and users get what they need quickly.
- SQL Foundation: Understanding relational algebra makes it easier to write better queries and work with databases more effectively.
- Data Integrity: It keeps data accurate and consistent, which is especially important in fields like healthcare, where reliable information can make all the difference.
- Informed Decisions: Proper data management leads to better business insights, benefiting industries like banking and e-commerce.
In short, relational algebra isn’t just a theory—it’s what makes managing large amounts of data possible and efficient in the real world.
Conclusion
In short, database design is all about creating organized, efficient systems that keep data accurate and easy to manage. The concepts we’ve covered, from relational models and ER diagrams to cardinalities and normalization, are the building blocks for a strong database. Understanding relational algebra helps us write better queries, and the ACID properties ensure our data stays reliable even when things go wrong. This unit has shown me how good database design is crucial for making smarter decisions and driving success in the real world, especially as data becomes more complex.