
Unit 6 - Indexing and Query Processing
Introduction
Before this unit, I thought indexing was just something databases used to “speed up” queries, without knowing exactly how or why. I also had no idea how complex query processing really was behind the scenes.
Unit 6 helped me understand the mechanics of indexing, including how databases organize and retrieve data efficiently, and how query processing and optimization play a critical role in performance. Initially, some parts (like B+ trees and query cost models) were challenging, but doing examples and using EXPLAIN ANALYZE in PostgreSQL made things clearer.
Important Lessons from Unit 6
What Are Indexes?
An index is like a lookup table that helps the database find records faster — instead of scanning the whole table, it can go straight to the relevant data.
Without indexes, simple queries would be painfully slow, especially on large tables. I now understand why efficient indexing is critical in any real-world database.
Types of Indices
- Ordered Indices
- Data is stored in sorted order.
- Two types:
- Clustering Index (Primary): Table is sorted based on the index.
- Non-clustering Index (Secondary): Table isn’t sorted, but index still provides pointers.
- Dense vs Sparse Index
- Dense: Every search key has an entry.
- Sparse: Only some keys have entries; used with sorted tables.
- Hashed Indices
- Uses a hash function to map keys to buckets.
- Great for equality queries, but not good for range queries.
- Example:
CREATE INDEX ON users USING hash (id);
Multilevel Indexing
Indexes themselves can become too big to store in memory.
Multilevel indexing solves this by adding a smaller, higher-level index that helps locate entries in the main index more efficiently.
Steps:
- Search the outer index in memory.
- Find the block in the inner index.
- Locate the record.
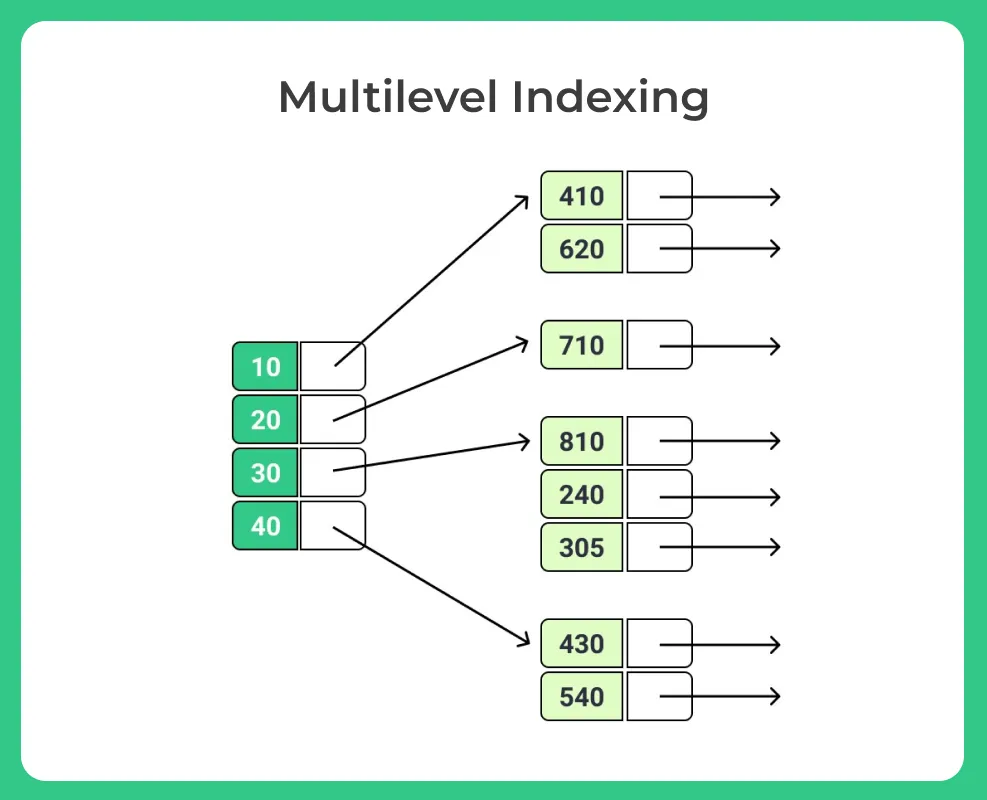
This is similar to searching in layers, making lookups much faster for huge datasets.
B Tree and B+ Tree
At first, I found tree structures confusing, but after reviewing diagrams and walkthroughs, I grasped the key differences:
- B Tree: Keys and data are stored in both internal and leaf nodes.
- B+ Tree: Data is only in leaf nodes. Internal nodes act as guides.
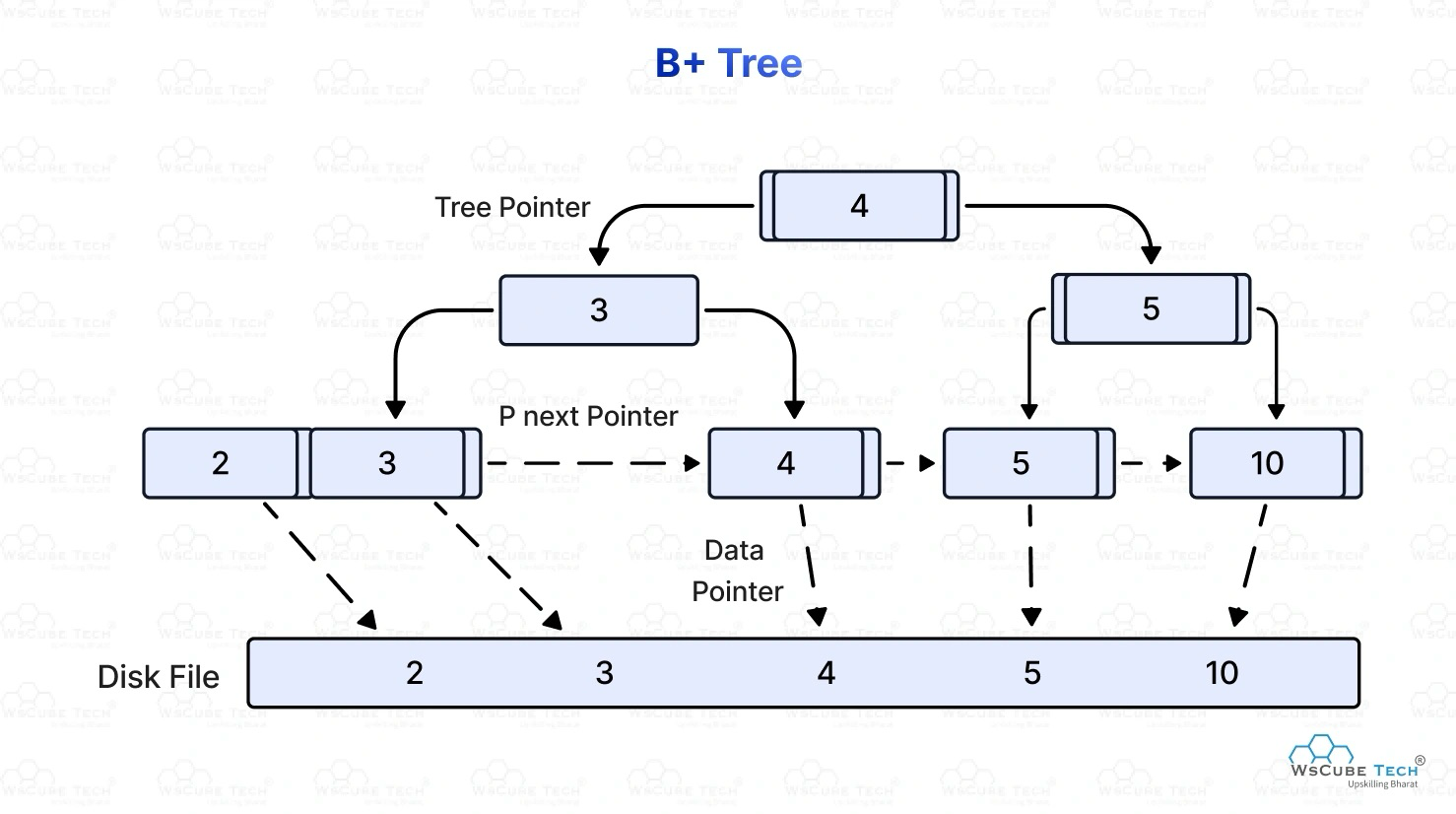
✅ B+ Trees are self-balancing, optimized for disk access, and widely used in real databases (like PostgreSQL).
✅ All leaf nodes are at the same level, making range queries faster and easier.
Query Processing
SQL is declarative, which means it doesn’t say how to run a query — just what we want.
The database has to:
- Parse and translate the SQL query into internal structures.
- Create a query evaluation plan using relational algebra.
- Choose the best plan (cost-wise) to execute.
A query evaluation plan is like a recipe. There are many ways to cook the same dish — the optimizer picks the one that costs the least time or resources.
Query Execution and Optimization
There are two main ways to execute query operations:
- Materialization: Store intermediate results in temporary tables.
- Pipelining: Stream results between operations (faster, less disk use).
The optimizer chooses between different plans using a cost-based model, looking at:
- Disk I/O cost
- CPU cost
- Statistics about table size and indexes
Example cost formula:
Cost = (number of blocks * transfer time) + (number of seeks * seek time)
Physical and Logical Plans
- Logical Plan: Shows what to do (e.g., join, filter).
- Physical Plan: Shows how to do it (e.g., nested loop join vs hash join).
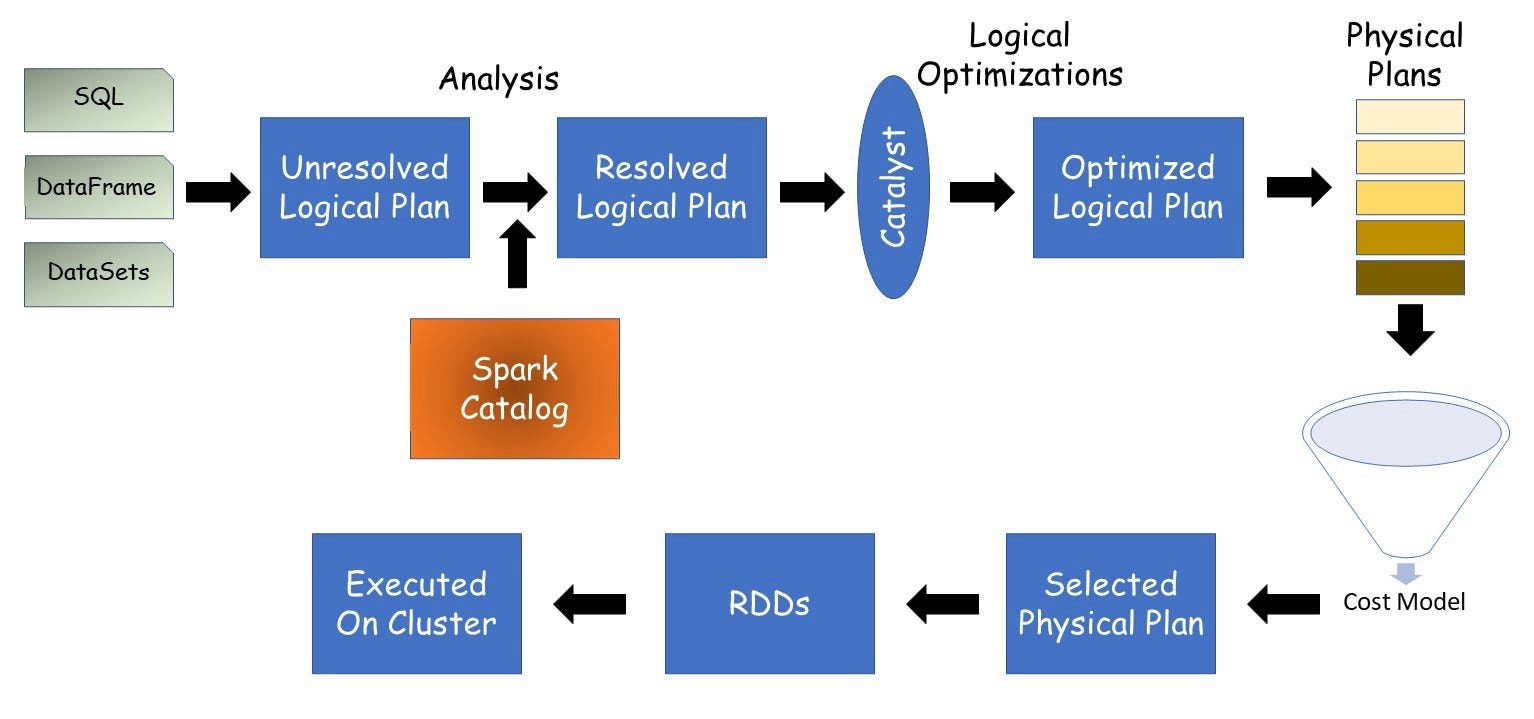 Sometimes, the order of joins can dramatically change performance.
Sometimes, the order of joins can dramatically change performance.
Optimizers reorder joins, apply heuristics, and use equivalence rules to find better alternatives.
My Experience and Reflections
I’ll admit — at first I was overwhelmed. Index types, cost formulas, and B+ trees all seemed complicated. But as I explored examples in PostgreSQL and read through the materials, things started to click.
Using EXPLAIN ANALYZE helped me see how queries actually get executed and how indexes improve speed.
- Example:
EXPLAIN ANALYZE SELECT * FROM properties WHERE price > 500000 AND city = 'San Francisco';This command shows the actual execution plan and runtime statistics, letting me see whether the database uses indexes or scans the whole table.
I also learned that:
- Not every index is helpful — sometimes it can slow things down.
- Understanding how queries are processed helps write better SQL.
- Optimizing queries isn’t just for big companies — it’s a must for any serious project.
Conclusion
Unit 6 taught me the real importance of indexing and how queries are processed and optimized.
What I once thought was “just SQL” turned out to be a well-orchestrated process involving translation, planning, and execution.
Now, I not only know how to create indexes — I understand when and why to use them, and how to think about query performance more critically.
In the future, I’ll definitely apply these skills in real-world projects, especially when working with large databases where performance matters most.