
Unit 7 - Transactions, Concurrency Control, and Recovery Systems
Introduction
Before diving into Unit 7, I assumed databases were simply digital filing cabinets—just store the data and run queries. But this unit completely shattered that illusion. I hadn’t realized how much complexity is involved in making sure data remains accurate, even when multiple people are accessing it at the same time or when something goes wrong like a system crash.
After studying this unit, I now understand that databases rely on:
- Transactions to group operations together safely
- Concurrency control to manage multiple users accessing data simultaneously
- Recovery systems to bring everything back to a consistent state when failures happen
It’s honestly incredible how much thought and engineering goes into ensuring data integrity behind the scenes. Learning about ACID properties in particular was a huge eye-opener—it made me appreciate just how much trust we place in database systems every day.
Important Lessons from Unit 7
Understanding Database Transactions (Lesson 18)
The backbone of reliable database systems is the transaction—a group of operations that must be executed as a single unit. Either all the operations in a transaction succeed, or none do. A classic example is transferring money from one account to another. If the debit happens but the credit doesn’t, the data becomes inconsistent, which is unacceptable in systems like banking.
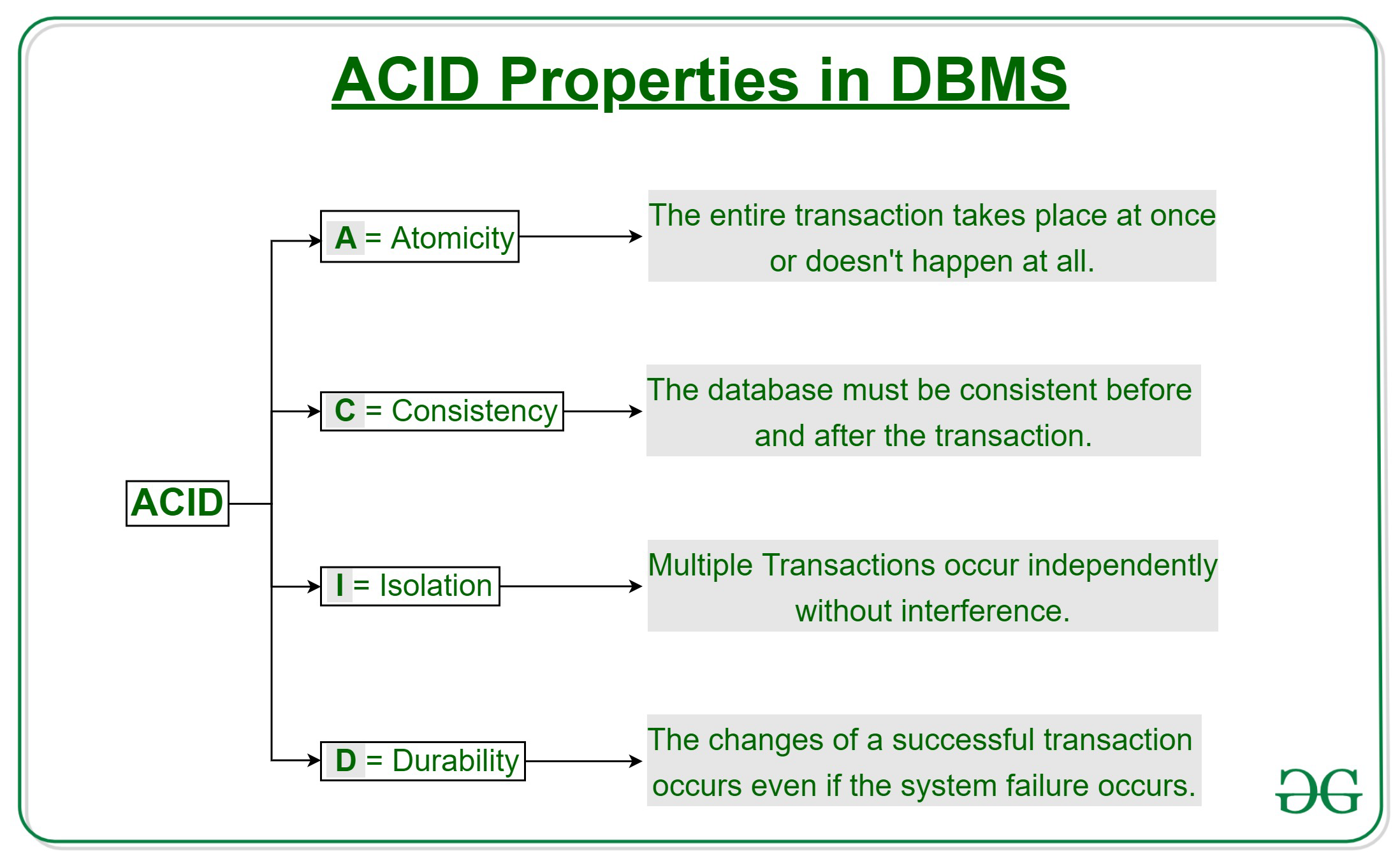
ACID Properties
To prevent inconsistencies, transactions are governed by the ACID properties:
- Atomicity: All steps in the transaction must complete or none at all
- Consistency: The database must start and end in a consistent state
- Isolation: Transactions appear to run independently, even when executed concurrently
- Durability: Once a transaction is committed, its effects are permanent—even if the system crashes
Here’s a basic example of a transaction in SQL:
BEGIN;
UPDATE accounts SET balance = balance - 50 WHERE account_name = 'A';
UPDATE accounts SET balance = balance + 50 WHERE account_name = 'B';
COMMIT;
Each of these ACID properties plays a critical role in maintaining the correctness of this operation.
Transaction States
Transactions go through multiple states such as:
- Active
- Partially Committed
- Failed
- Aborted
- Committed
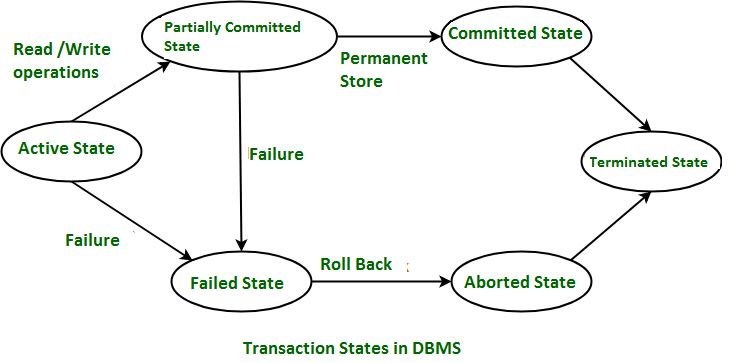
These states help the database system manage what actions to take if something goes wrong mid-transaction, ensuring either rollback or successful completion.
Concurrency Control (Lesson 19)
When multiple users access a database at once, things can get messy if their operations overlap in a way that causes conflicts. Concurrency control is the set of techniques used to handle these situations.
Transaction Schedules and Serializability
A schedule determines the order in which transaction operations are executed. A serial schedule is one where transactions execute one after another. In contrast, non-serial schedules interleave operations. Not all non-serial schedules are bad—if a schedule produces the same outcome as some serial schedule, it’s called serializable, and it’s considered safe.
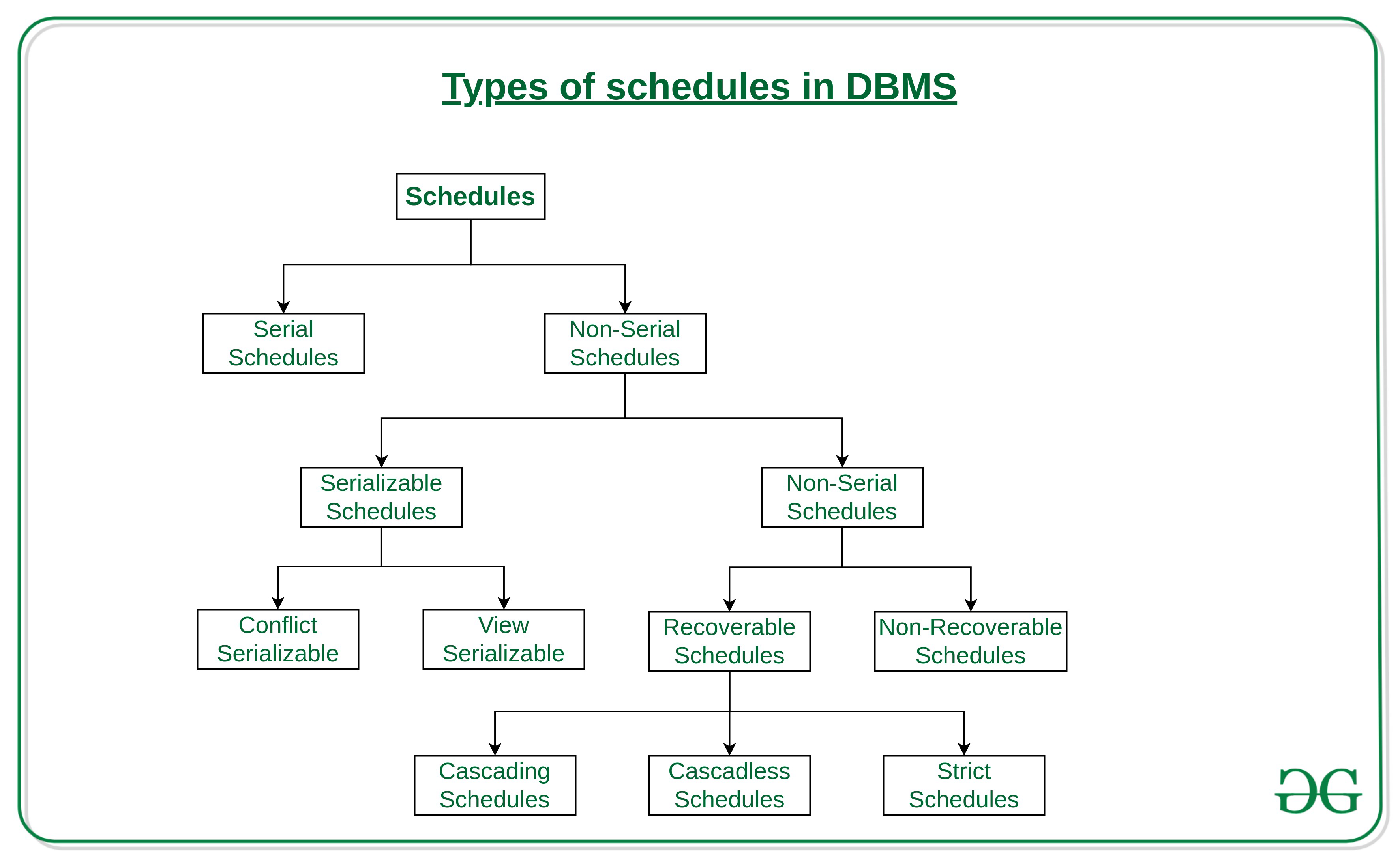
Locks: Shared vs Exclusive
The primary tool for concurrency control is the lock. There are two basic types:
- Shared (S): Allows multiple transactions to read a data item
- Exclusive (X): Allows a transaction to both read and write a data item, blocking others
The lock compatibility matrix ensures that only compatible locks can coexist, preserving consistency:
| Lock Type | Shared (S) | Exclusive (X) |
|---|---|---|
| Shared (S) | ✅ | ❌ |
| Exclusive (X) | ❌ | ❌ |
Two-Phase Locking (2PL)
To ensure serializability, databases use two-phase locking:
- Growing phase – The transaction acquires locks
- Shrinking phase – The transaction releases locks
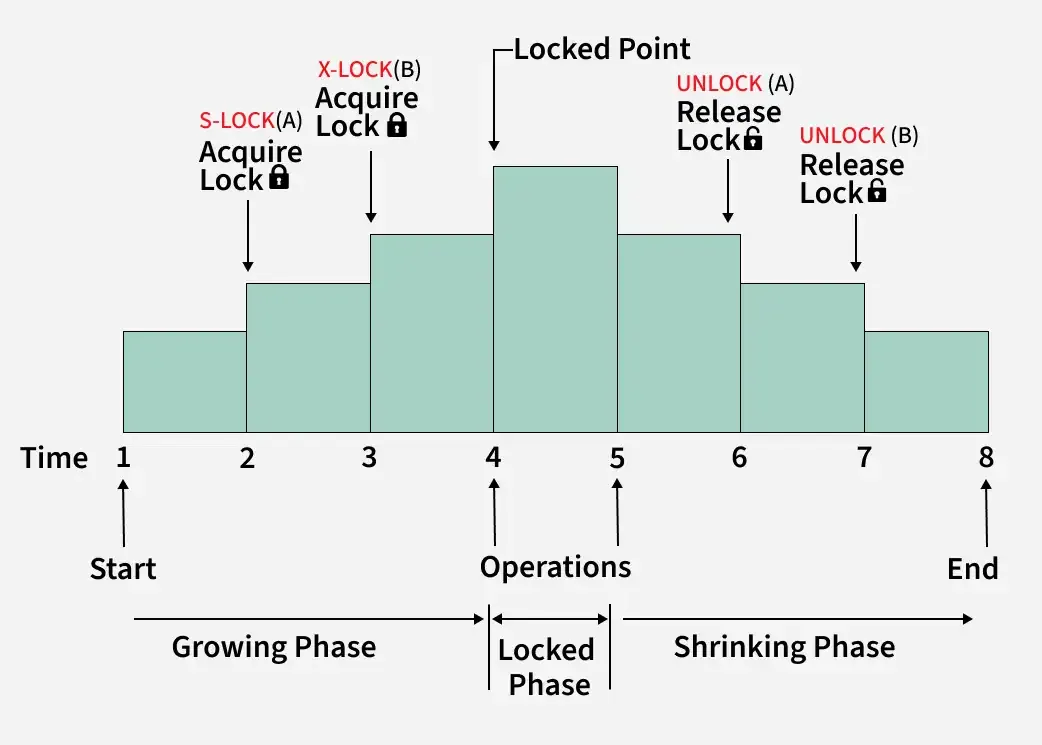
Once it releases a lock, it cannot acquire any new ones. This structure helps prevent anomalies.
Deadlocks and Prevention
Deadlocks happen when two transactions wait on each other indefinitely. We learned two approaches to handle them:
- Detection: Build a “waits-for” graph and look for cycles
- Prevention: Use techniques like wait-die or wound-wait to decide which transaction should proceed or abort based on timestamps
Lock Granularity and Intention Locks
Locks can be applied at various levels: tuples (rows), pages, tables, etc. Finer granularity increases concurrency but adds overhead. Intention locks like IS, IX, and SIX help manage these hierarchies efficiently.
Other Approaches
Besides locking, databases use:
- Timestamp Ordering
- Optimistic Concurrency Control
- Multi-Version Concurrency Control (MVCC)
These techniques offer alternatives that may improve performance or avoid blocking altogether, depending on the application.
Database Recovery (Lesson 20)
Even with perfect transactions and concurrency control, systems can still crash. That’s where recovery systems come in.
Log-Based Recovery
The most common approach is Write-Ahead Logging (WAL). Every change is recorded in a log before it’s written to the database. Each log record includes:
- Transaction ID
- Data item
- Old value
- New value
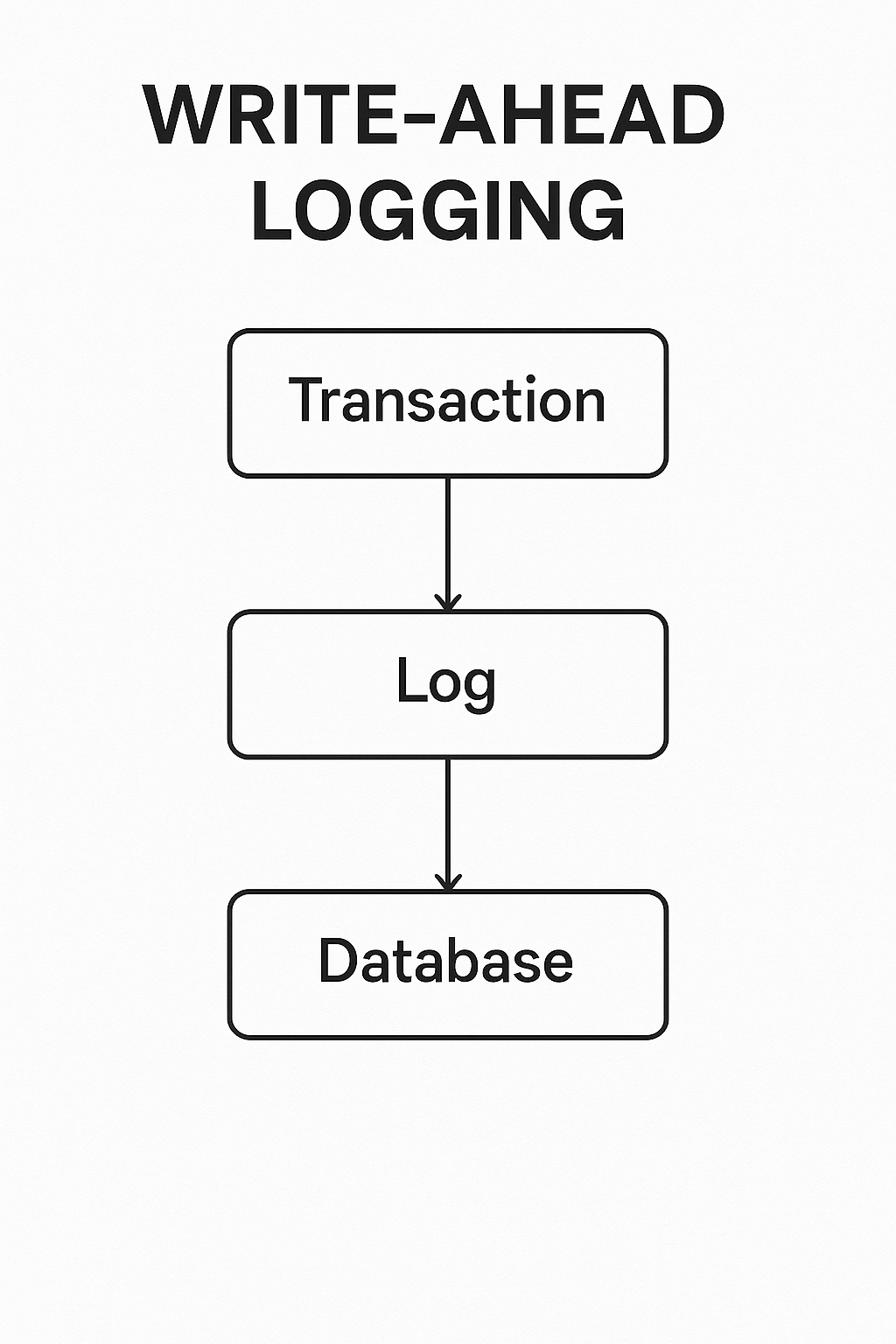
This lets the system undo incomplete transactions or redo completed ones after a crash.
Undo vs Redo
- Undo: Brings the database back to the state before an uncommitted transaction
- Redo: Re-applies the effects of committed transactions to ensure their changes persist
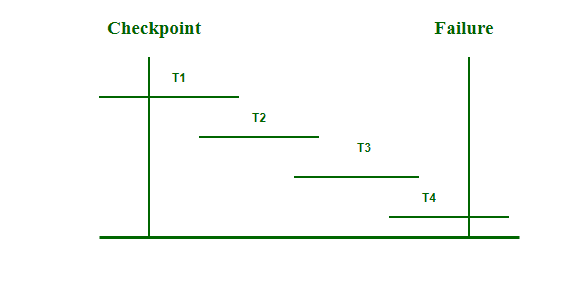
Checkpoints and Fuzzy Checkpoints
Checkpoints help speed up recovery by limiting how far back the system must scan the log. Fuzzy checkpoints allow transactions to continue during the checkpoint process, increasing system availability.
ARIES Recovery Algorithm
ARIES is a robust recovery technique that uses three steps:
- Analysis – Determine what needs to be undone/redone
- Redo – Re-apply operations from the log
- Undo – Rollback incomplete transactions
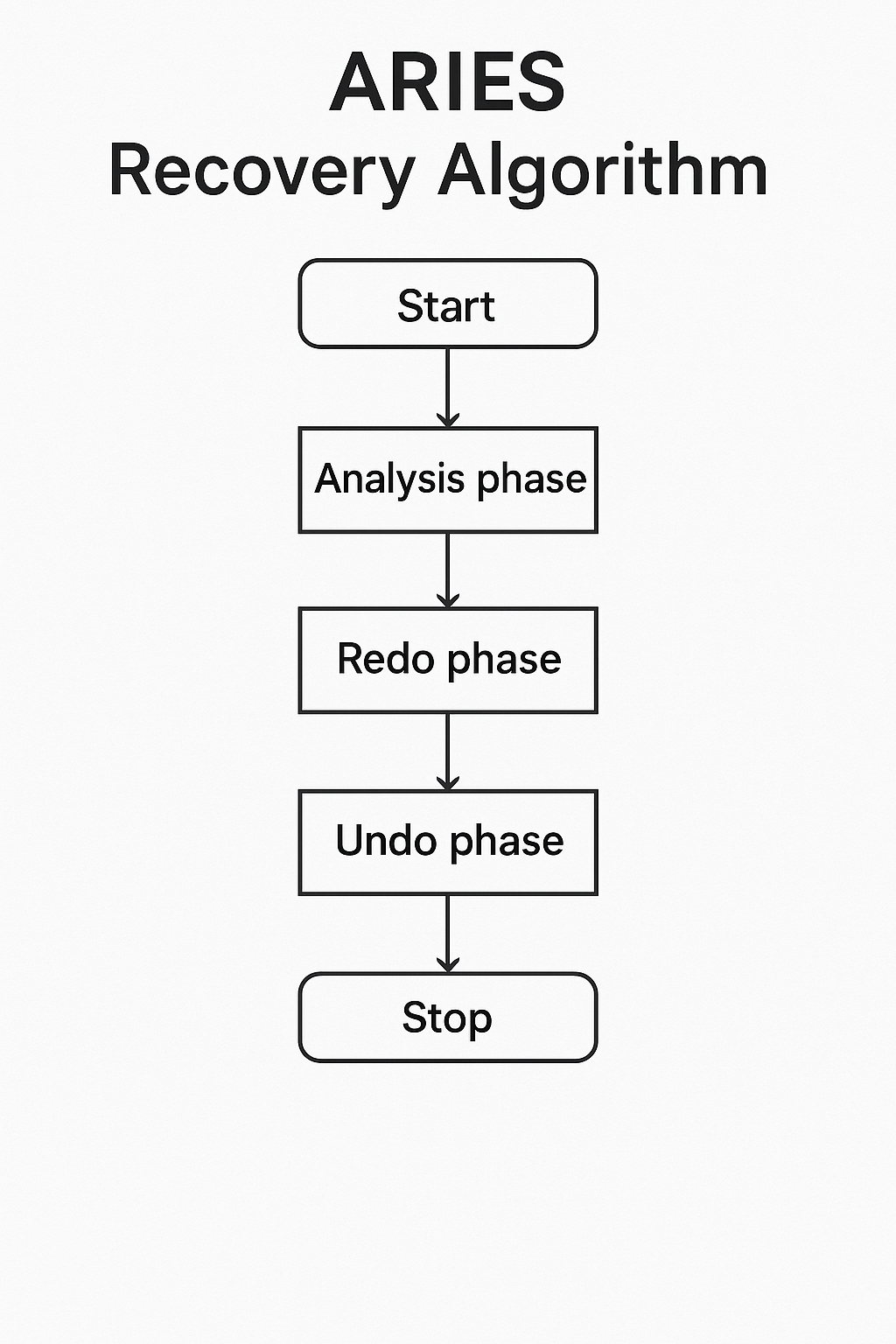
It’s based on WAL, supports “steal” and “no-force” buffer policies, and handles crashes gracefully.
Remote Backups and High Availability
We also explored remote backup systems that use log shipping to keep a remote copy of the database up-to-date. If the primary system crashes, the backup takes over. This is critical for systems that require high availability.
My Experience and Reflections
This unit challenged me more than any previous one. I kept mixing up ACID properties at first, especially isolation and atomicity. When we practiced transaction creation in PostgreSQL, I accidentally skipped the BEGIN statement, and nothing was treated as a transaction—took me a while to figure that out!
Concurrency control was particularly hard to wrap my head around. At first, the lock compatibility table just looked like a confusing mess. But after seeing it applied in practical scenarios, it started to click. Deadlocks made more sense because I could visualize them as people stuck in a hallway refusing to move.
The most mind-blowing part was recovery. I never realized databases were capable of “going back in time” to undo or redo changes after a crash. It made me think of the database as having a memory of everything that happened—kind of like a time machine.
Implementing a simple recovery system in one of our labs helped me understand the WAL concept better. But the ARIES algorithm is still tough for me. I get the basic steps, but the details—like how log sequence numbers (LSNs) are used—are something I’m still reviewing.
Conclusion
Unit 7 gave me a whole new appreciation for what goes on under the hood in a database system. It’s not just about SELECT and INSERT—it’s about ensuring reliability, managing concurrency, and recovering from failure. I now understand how databases ensure that our most critical systems—like banking, e-commerce, and air traffic control—remain consistent and safe no matter what.
The most valuable lesson for me was the importance of transactions and ACID properties. I feel more confident about building systems that need to handle real-world complexity, and I’m excited to explore more advanced topics like distributed transactions and fault-tolerant systems.
I still get a bit lost in serializability graphs and ARIES internals, but I know that’s part of the learning process. I’ve come a long way from thinking databases just “store stuff,” and I’m eager to apply these concepts in future projects—maybe a mini banking or reservation system with real transaction handling and recovery features!